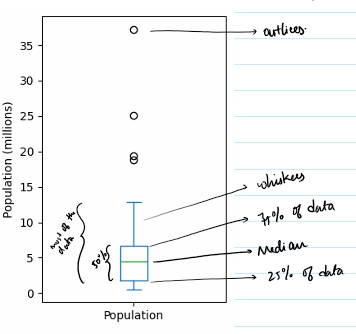
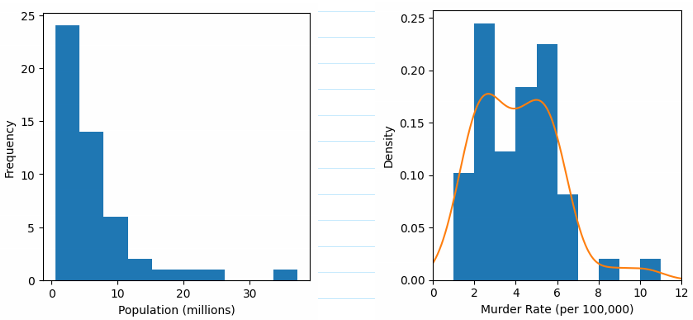
- Sometimes quality is better than quantity. Smaller samples give better description about the data that the population itself. This is one of the reason why a better sampling is required.
Todays topics:
Sampling
- Bias:
- Statistical bias refers to measurement errors or sample errors that are produced by either during measurement or during sampling.
- It is important to differentiate between these two biases and several methods were developed to reduce this sampling bias. One of the method is Random Sampling
- The most basic sampling is Random sampling. We take a random member of a population to the sample. All the members in the population has an equal chance of getting selected. In selecting the next sample, we can Replace the picked up member back to the population (called as Replacement) or we can leave it out if population for the next samples (without Replacement).
-To achioeve a better representation of the population through sampling, it could be useful to look at questions like:
- Do we need to startify the data into smaller sub groups of data with similar properties before sampling?
- Does assigning weights to different stratified subsets to achieve better sample sizes?
- Sample Means vs Population Means:
- The mean of the sample($\bar{x}$) is often different from the mean of the population ($\bar{\mu}$).This is important because the variation of the sample means across different samples can give a lot of information about the population.
- A normal procedure to model a dataset is:
- To specify a hypothesis (more about this later)
- Conduct a well designed Experiment to test the hypothesis.
- Have results
- But this is not what happens in general. The Person modeling the dataset may go on an extensive search through the dataset in search of patterns and sooner or later, there comes a pattern. But the question is, is this really a pattern or just a Data snooping. Another interesting phenomenon is Data Snooping, it occurs when the data is extensively hunted through to find somethong interesting. This leads to
- Selection Bias:
- When a Datascientist or a statistician selects the samples selectively so that leads to a conclusion is called selection bias.
Sampling distribution of a statistic:
- As we discussed above, the distribution of the mean of a sample is important for infering information about the population. So in this section we look closer at sampling distributions
- Sampling metric is a metric calculated foa a sample
- Sampling distribution is the frequency distribution of a sample statistic over several samples. While data distribution is the frequency distribution of the individual data points.
- We can now, try to estimate this sampling distribution to see how far the sample statistic is from the population statistic (eg: mean)
- About Sampling Distribution:
- Sampling distribution of samples resembles bell curve.
- The above statement is governed by Central Limit Theorem (CLT)
Central Limit Theorem:
- It states that the means drawn from several samples will resemble a bell curve given:
- The sample size is large enough
- The values of data doesnt depart from normality too much.
- For a data scientist, CLT is not so important but for traditional statistics it is a very important theorem as it lays foundational grounds for Hypothesis testing, confidence intervals.
- A better method called boot strap is always available for estimating sampling distribution that does not assume that the sampling dist forms bell curves. (more on bootstrap later)
Standard Error:
- Population: You have a big, unknown group.
- Samples/Resamples: You take many samples of size $n$.
- Sample Metric: You calculate the mean ($\bar{x}$) for every single sample.
- Sampling Distribution: You plot all those means. Because of the CLT, they form a bell curve
- Now we can calculate the standard deviation of this bell curve to find the spread of the curve or the variability of the sample means
- But, the problem is we do not have to take several thousands of samples to estimate the sampling distribution. We can take one sample and then we can try to estimate ‘Standard Error’ for a sample and scatter it to remaining samples.
- Because, the shape of the curve is ‘bell curve’, we need two inputs for the normal distribution estimation. The mean and the standard deviation. This standard deviation is here called as ‘Standard Error’
- Standard Error is a single metric to measure the variability of sampling distribution.
- It is given by $SE = \frac{s}{\sqrt{n}}$ ; s = standard deviation
- From the above equation, we can deduce that that:
- As the sample size(n) increases, the Standard error decreases.
- This relation ship btwn SE and Sample size is reffered to as ‘Square root of n’ rule.
- When the SE to go down by a factor of 2 the sample size has to be increased by 4times.
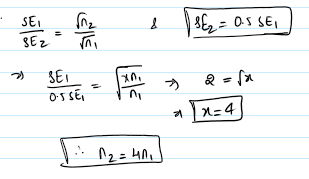
- While this method is useful in estimating SE, it has several con’s:
- Assumption of bell curve for the sampling dist
- The standard deviation of the sample is used for the estimation of SE. if the sample taken is by chance abnormal, this could mess up the SE estimation.
- This method only works for the metric mean.
- This method of taking samples and estimating the SE is not efficient in statistical terms(not resourceful). There is another effective method called ‘BOOT STRAP’ method of resampling.